



 pro-iBiosphere wiki platform
pro-iBiosphere wiki platform
 RSS news
RSS news
The Coordination and Support Action pro-iBiosphere will come to an end by the 31st of August 2014. The project was launched for two years to investigate ways to increase the accessibility of biodiversity data, improve the efficiency of its curation and increase the user base of biodiversity data consumers and applications. Ten of its key major outcomes have been summarised in the "pro-iBiosphere final brochure".
The project delivered a series of recommendations on various pressing topics to the wider biodiversity informatics community, for instance, on how to improve the use of digital infrastructures among taxonomists, on how to addresses barriers to the open exchange of biodiversity knowledge that arise from European laws, in particular European legislation on copyright and database protection rights. The recommendations have been documented in various pro-iBiosphere deliverables (here available).
The project conducted 5 pilots and organised a total of seven meetings. The enthusiasm, involvement and breadth of the community participation to these meetings was very impressive!. The pro-iBiosphere final event took place from the 10th - 12th of June 2014 at the Bouchout Castle (Botanic Garden Meise, Belgium). An audience consisting of more than 75 persons participated in the event. Activities organised during the event included a Workshop on the Biodiversity Catalogue, Demonstrations on the project pilots, Demonstrations on the outcomes of the Data Enrichment Hackathon, a Training on WikiMedia, a Poster session and the Final Conference.
A major highlight of the Final conference was the official launch and ceremony of the Bouchout Declaration for Open Biodiversity Knowledge Management. At present (August 2014) more than 170 institutions and 90 organisations have signed the Declaration. For more information please see the news items "The Bouchout Declaration: A commitment to open science for better management of nature" (published below on page # and "The Bouchout Declaration: A contribution from the biodiversity community to Open Digital Science" (published on the Digital Agenda for Europe website).
The conference proceedings, including an event report (detailing the statistics and outputs of the Final Conference), a Storify (i.e. a collection of tweets and pictures) and pictures, are available here.
It has been a pleasure working with all of you!
Soraya Sierra
pro-iBiosphere Project Leader

 Results are also presented in an easy to use interactive SCALETOOL, specifically developed for the needs of policy and decision-makers. The tool also provides access to a range of biodiversity data and driver maps compiled or created in the project.
Results are also presented in an easy to use interactive SCALETOOL, specifically developed for the needs of policy and decision-makers. The tool also provides access to a range of biodiversity data and driver maps compiled or created in the project.
Creative Commons, a nonprofit organization that enables the sharing and use of creativity and knowledge through free legal tools, just signed the Bouchout Declaration in line with its vision and commitment to open science Data.
Creator and steward of the legal and technical infrastructure that allows open licensing of content, the non profit organization entirely supports the Declaration which exhorts the use of licenses or waivers to grant all users a free right to copy, use, distribute, transmit and display the work publicly, as well as to build on the work and to make derivative works, subject to proper attribution consistent with community practices.
Creative Commons, which has participated in the activities that led to the Joint Declaration of the Data Citation Principles and advocates the use of persistent identifiers to allow discovery and attribution of resources, encourages the Declaration to promote tracking the use of identifiers in links and citations. This methods ensures that sources and suppliers of data are assigned credit for their contributions and Persistent identifiers for data objects and physical objects such as specimens, images and taxonomic treatments with standard mechanisms to take users directly to content and data.
Creative Commons, which works assiduously on fostering the promulgation of open policies and practices, naturally encourages the declaration calls for Policy developments to foster free and open access to biodiversity data.
If you too believe that open biodiversity information is crucial for science and society, join the movement and sign the Bouchout Declaration!


The next BioVel meeting will take place in Paris, France on November 13, 2014.
This one-day event, entitled "BioVeL : In Practice and in future" aims at presenting the achievments, experiences gained and lesson learnt from the BioVel initiative which has been working on building a virtual laboratory for biodiversity research. This event will also provide an opportunity to introduce BioVel plans for the future.
BioVeL is a pilot implementation of some of the core ideas from the LifeWatch Preparatory Phase. In the past three years the project has been working with the biodiversity research community to construct, test, and revise some essential elements of a robust e-infrastructure for biodiversity and ecosystem research.
The event will be structured around the 3 key goals that encapsulate the BIH2013 initiative.
• Integration: Making better use of existing data and tools.
• Cooperation: Working together towards a global biosphere model.
• Promotion: Informatics leadership to serve the needs of science and policy.
For more information and registration, click here.
For any additional information, please contact: [email protected].
Find out more on the BioVel project a www.biovel.eu.

The article published on July 7, 2014 on the European Commission Digital Agenda website presents the Bouchout Declaration launched by the project on June 12, 2014 like a major contribution from the biodiversity community to Open Digital Science.
The article stresses that only three weeks after being launched, this unprecedented declaration have already been endorsed by more than 70 institutions and 140 individuals from 40 countries around the Globe. A total success!
With their signature, the management of the organizations and individuals encourage an overarching approach to Biodiversity Knowledge Management based on the principles of Open Access, the use of unique stable identifiers for data objects, resolution mechanisms that take users directly to content and data, registries that allow discovering, access and re-use of the data as well as fostering an ongoing dialogue to refine the concept of Open Biodiversity Knowledge Management.
The Bouchout Declaration has been translated into 8 languages available online on the Bouchout Declaration website.
Follow the Bouchout Declaration on twitter @bouchoutdec
Read the full article by the European Commission online at www.ec.europa.eu/digital-agenda

The pro-iBiosphere Final Conference successfully took place in Meise on June 12, 2014 at the Bouchout Castle in the Botanic Garden Meise in the North of Brussels. More than 75 participants from the biodiversity and/or e-Infrastructures community joined the active discussions while (i) reviewing project results and the key areas of improvement in the design and implementation of an OBKMS and (ii) providing recommendations on future research needs for the preparation of the next WP 2016-2017 of EU Horizon 2020 Framework Programme for Research and Innovation.
On this occasion, one of the major highlight of the conference has been the official launch ceremony of the Bouchout Declaration on Open Biodiversity Knowledge Management System (OBKMS) in which key biodiversity institutions officially signed it together and the release of the Bouchout Declaration website. Following the event, a total of 66 organizations and 116 individuals endorsed the Declaration. The Declaration has been translated into 8 languages available online on the dedicated website.
The Final Conference has been the last meeting organised among a series of activities, so-called pro-iBiosphere Final event, including (i) MS24 - Model Evaluation Workshop held on June 9-10, (ii) Training on Wikimedia, (iii) Biodiversity Catalogue (BioVeL) Workshop, (iv) Demonstrations on project pilots, (v) Demonstrations on outcomes of pro-iBiosphere Data Enrichment Hackathon and a Poster session organised during coffee breaks on June 11.
The proceedings of the Final Conference (updated agenda with presentations, final attendee list and pictures) with conclusions of each session are available on the wiki page.
An event report has also been produced and is available here detailing the Final Conference objectives, programme, promotion, audience and outputs.
For any additional information, please contact us at [email protected].

The ICT Proposers' day 2014 (#ICTpropday) is a networking event organised by the European Commission and will be held in Florence, Italy on the 9th and 10th of October 2014.
This event is specifically dedicated to networking and promoting research and innovation in the field of Information and Communication Technologies. It will focus on networking for the Horizon 2020 Work Programme 2015.
It is free of charge and offers an exceptional occasion to build quality partnerships as it will connect academia, research institutes, industrial stakeholders, SMEs and government actors from all over Europe. The registration to attend the event is now open.
Find out more on ICT Proposers’ Day website. Register now here.

The BioVeL project, supporting research on biodiversity by offering computerized tools ("workflows") to process large amounts of data from cross-disciplinary sources is proud to announce the release of its Spring 2014 newsletter.
The 5th BioVeL newsletter focuses on the latest developments with the e-laboratory, especially with its new portal. It also addresses the sustainability of the project.
pro-iBiosphere and the BioVeL project have been in close contact in the past months while pro-iBiosphere became a " BioVeL friend ", supporting the objectives of the BioVeL project and the BioVeL project participated in the pro-iBiosphere Final Event while organising a Workshop on Biodiversity Catalogue on June 11, 2014 and financially sponsoring catering and lunch on that day.
The Spring 2014 BioVeL newsletter is available online here.



The Bouchout Declaration is a major output from the pro-iBiosphere project.
The Bouchout Declaration is an opportunity for those organizations, initiatives and individuals who create, manage and use biodiversity information, and who believe in the opportunities and potential of the big data world, to declare their support of the Open Access agenda.
By endorsing the principles of Open Access and discoverability of data, the signatories strengthen the arguments that will be put to governments and funding bodies, and will accelerate the maturation and evolution of Open Biodiversity Knowledge Management, making biodiversity sciences more relevant, innovative, and responsive to societal needs.
As of to-date, 73 signatories from 26 countries share the vision expressed in the Bouchout Declaration.
The Bouchout Declaration official launch took place today during the pro-iBiosphere Final Conference at Bouchout Castle, Botanic Garden Meise in Belgium. The offical Website (bouchout-declaration.org) has been unveiled on this occasion.
If you also share the vision of the Bouchout Declaration, we invite you to sign this document here.


The new workflow demonstrates a re-publication of a volume of Flora Malesiana in a semantically enriched HTML edition available on the newly launched, Advanced Books publishing platform. The platform was demonstrated today at the EU funded pro-iBiosphere project which supported, in part, the re-publication of Flora Malesiana.
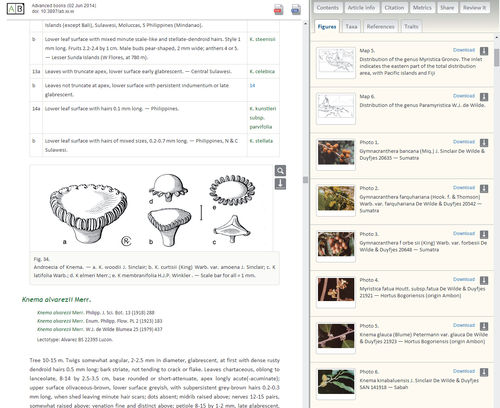
The new pilot, developed by Pensoft Publishers in a cooperation with the Naturalis Biodiversity Center, Plazi, and Botanischer Garten und Botanisches Museum Berlin-Dahlem (BGBM), demonstrates how a fundamental book in natural history can start a new life with Advanced Books. Re-publication of the Flora of Northumberland & Durham, published in 1838, will be the next to appear as a result of a collaboration between the Botanical Garden Meise National Botanic Garden of Belgium and Pensoft.
Flora Malesiana is a systematic account of the flora of Malesia, the plant-geographical unit spanning six countries in Southeast Asia: Indonesia, Malaysia, Singapore, Brunei Darussalam, the Philippines, and Papua New Guinea. The plant treatments are not published in a systematic order but as they come about by the scientific efforts of some 100 collaborators all over the world.
With the new platform, such scientifically important historical monographs, enriched with additional information from up-to-date external sources related to organisms' names, species treatments, information on their ecology, distribution and conservation value, morphological characters, etc., become freely usable for anyone at any place in the world.
The re-publication in advanced open access comes with the many other benefits of the digitization and markup efforts such as data extraction and collation, distribution and re-use of content, archiving of different data elements in relevant repositories and so on.
"Advanced Books will bring many outstanding scientific monographs to a new life, however the platform is not only restricted to e-publish our legacy literature." commented Prof. Lyubomir Penev, Managing Director of Pensoft. "New books are mostly welcome on the platform, joining their historical predecessors in an open, common, human- and machine-readable, data space for the benefit of future researchers and the society in general" concluded Prof. Penev.
As a part of the series of final project utputs a new pro-iBiosphere article published in the open access journal ZooKeys assesses the need and future for building an Open Biodiversity Knowledge Management System (OBKMS) - the infrastructure for a system that will intelligently manage and integrate digital biodiversity information.
Background. The 7th Framework Programme for Research and Technological Development is helping the European to prepare for an integrative system for intelligent management of biodiversity knowledge. The infrastructure that is envisaged and that will be further developed within the Programme "Horizon 2020" aims to provide open and free access to taxonomic information to anyone with a requirement for biodiversity data, without the need for individual consent of other persons or institutions. Open and free access to information will foster the re-use and improve the quality of data, will accelerate research, and will promote new types of research. Progress towards the goal of free and open access to content is hampered by numerous technical, economic, sociological, legal, and other factors. The present article addresses barriers to the open exchange of biodiversity knowledge that arise from European laws, in particular European legislation on copyright and database protection rights.
We present a legal point of view as to what will be needed to bring distributed information together and facilitate its re-use by data mining, integration into semantic knowledge systems, and similar techniques. We address exceptions and limitations of copyright or database protection within Europe, and we point to the importance of data use agreements. We illustrate how exceptions and limitations have been transformed into national legislations within some European states to create inconsistencies that impede access to biodiversity information.
Conclusions. The legal situation within the EU is unsatisfactory because there are inconsistencies among states that hamper the deployment of an open biodiversity knowledge management system. Scientists within the EU who work with copyright protected works or with protected databases have to be aware of regulations that vary from country to country. This is a major stumbling block to international collaboration and is an impediment to the open exchange of biodiversity knowledge. Such differences should be removed by unifying exceptions and limitations for research purposes in a binding, Europe-wide regulation.
Original Source:
Egloff W, Patterson DJ, Agosti D, Hagedorn G (2014) Open exchange of scientific knowledge and European copyright: The case of biodiversity information. ZooKeys 414: 109–135. doi: 10.3897/zookeys.414.7717
Do not miss this unique opportunity and join us in Meise (Brussels) from June 10-12 to participate in this major event devoted to making fundamental biodiversity data digital, open and re-usable (organized by the pro-iBiosphere project funded by the European Commission DG Connect)!
This pro-iBiosphere Final Event is taking place at a crucial time for the development of new instruments for the future needs of biodiversity research through the preparation of the next WP 2016-2017 of EU Horizon 2020 Framework Programme for Research and Innovation.
Within this context, one of the main highlights of the conference will be to provide key recommendations and inputs from biodiversity experts to the European Commission.
In this context, if you plan to attend and have not yet registered, please do it here (free of charge).
Follow and contribute to the Final Event discussions while tweeting using the following hashtag: #pibmei !
For further information on this event please visit the dedicated wiki page here or contact us at [email protected].
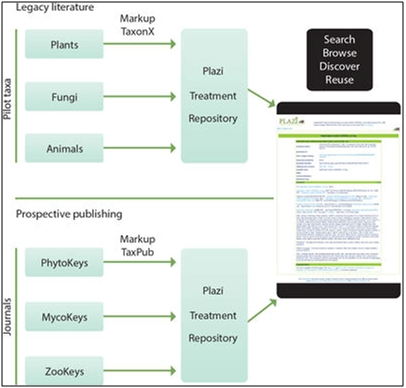
-
Step 1: Convert printed taxonomic articles/monographs to digital text format.
-
Step 2a: Mark up generic document features and domain-specific information (taxon treatments) and store the results at Plazi; and also
-
Step 2b: Export of newly published treatments marked up during the editorial process (for example in the journals ZooKeys, PhytoKeys and Mycokeys)
-
Step 3: Browse, search, export and re-use treatments coming from different sources.
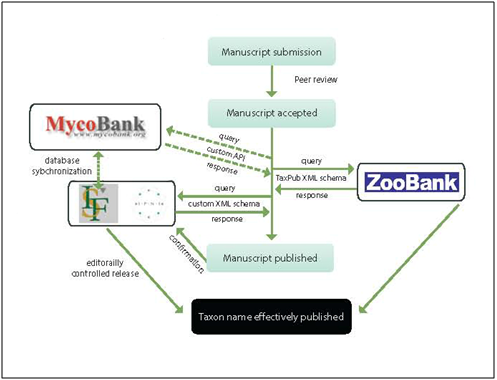
-
Step 1. XML message from the publisher to the registry on acceptance of the manuscript containing the type of act, taxon names, and preliminary bibliographic metadata; the registry will store the data but not make these publicly available before the final publication date.
-
Step 2a. Response XML report containing the unique identified of the act as supplied by the registry and/or any relevant error messages.
-
Step 2b. Error correction and d-duplication performed manually: human intervention at either registry’s or publisher’s side (or at both).
-
Step 3. Inclusion of registry supplied identifiers in the published treatments (protologues, nomenclatural acts).
-
Step 4. Making the information in the registry publicly accessible upon publication, providing a link from the registry record to the artice.

- Steps forward 1: Implementation of HTTP-URIs by 8 major institutions for their collection objects by October 2013 and recommendations for further topics to be explored in detail.
- Steps forward 2: Agreement on the BiodiversityCatalogue as a global registry for biodiversity related services. Improvement recommendations for it to be able to fill this role even better, registration of services available now.
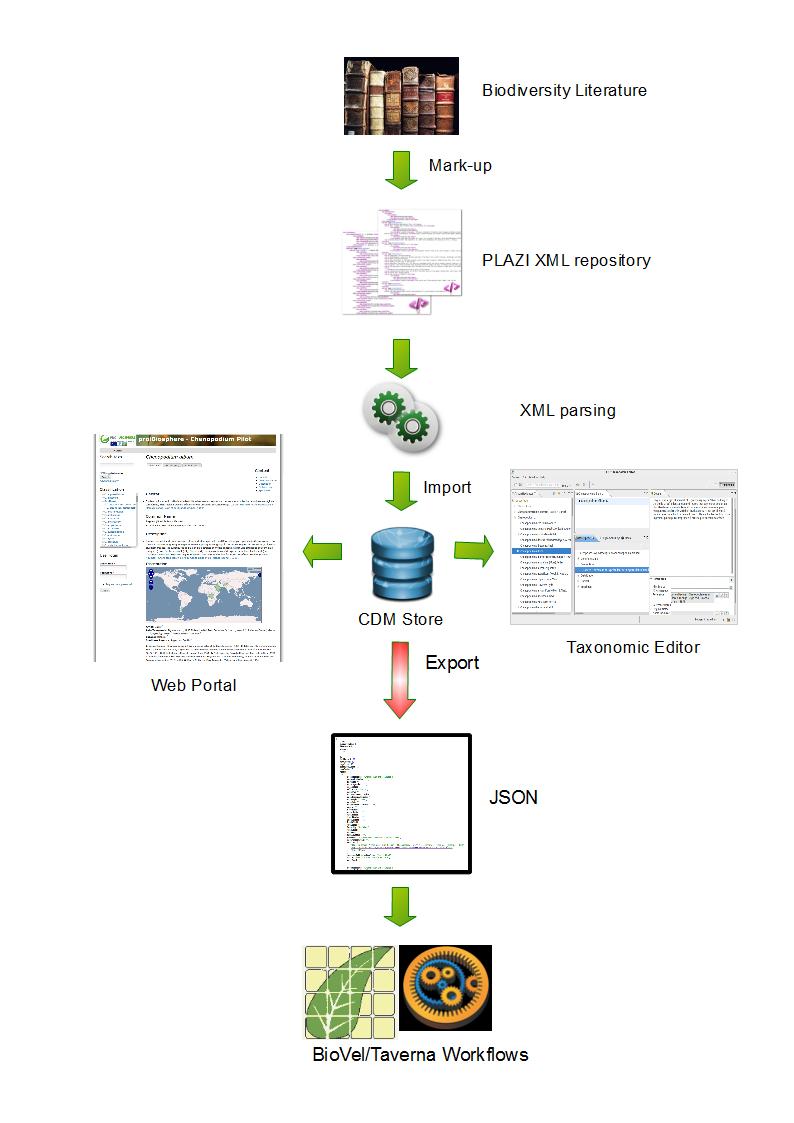
- Steps forward 3: Workflow improvement between the Plazi document registry and the Common Data Model (CDM)-based EDIT Platform for Cybertaxonomy (http://wiki.pro-ibiosphere.eu/wiki/Pilot_3 ). In the course of this a markup granularity table evolved. The pro-iBiosphere pilot portals visualize the data results at different stages and show the possibilities for scientists willing to mark up their data. The markup granularity table explains in detail work load and connected output gain.
-
To facilitate re-use and enhancement of biodiversity knowledge by a broad range of stakeholders, such as ecologists and niche modelers.
-
To foster a community of experts in biodiversity informatics and to build human links between research projects and institutions.
Italian National Research Center), Christian Brenninkmeijer (University of Manchester), Hannes Hettling (Naturalis Biodiversity Center), Rutger Vos (Naturalis Biodiversity Center)
[2] http://phenoscape.org/
[3] http://phenoscape.org/wiki/Phenex
[4] http://www.plantontology.org
[5] http://obofoundry.org/wiki/index.php/PATO:Main_Page
[6] Gkoutos, G. V., Green, E. C., Mallon, A.-M. M., Hancock, J. M., and Davidson, D. (2005) Using ontologies to describe mouse phenotypes. Genome biology, 6(1).
[7] Mungall, C., Gkoutos, G., Smith, C., Haendel, M., Lewis, S., and Ashburner, M. (2010) Integrating phenotype ontologies across multiple species. Genome Biology, 11(1), R2+.
[8] Robinson, P. N. et al. (2008) The Human Phenotype Ontology: a tool for annotating and analyzing human hereditary disease. American journal of human genetics, 83(5), 610–615.
[9] http://www.jbiomedsem.com/content/4/1/43

